Another new model coming to Quick Subtitles

There will be a Quick Subtitles update out soon that adds OpenAI's Whisper model to the app as an optional transcription model. Why, you might ask? Well, I think each model has its own advantages.
- Apple's model is built into iOS/macOS already, so there's no extra storage required, and it's very fast and pretty accurate.
- NVIDIA's model requires a download, but is even faster, and sometimes is a bit more accurate.
- OpenAI's model also requires a download, it's much slower, but it also delivers better quality on average.
Personally, I think Apple's model is a really good balance and I really like that I'm able to bundle it into the app without requiring any third party dependencies or external downloads. That said, I did start to feel like I was losing a competitive advantage by only using this model, and I think giving users more options is a good thing in this case.
As a quick side note on Parakeet, if you are using that model today and you notice that sometimes the app sits at 0% for a little bit before rocketing through the rest, that's because Parakeet needs to "warm up" before processing sometimes. So if you just launched the app for the first time in a while, that first file may have a bit of a delay. I'm working on finding a clever way to get this warm-up to happen before you actually provide a file, but no timeline on that yet.
Performance
Let's start by looking at the performance difference between the models, which as a reminder, all run 100% locally on your device. Your audio files never ever ever get uploaded to any cloud service.
Below is how long it took to transcribe a 38-minute podcast episode across each model on an M4 Pro MacBook Pro.
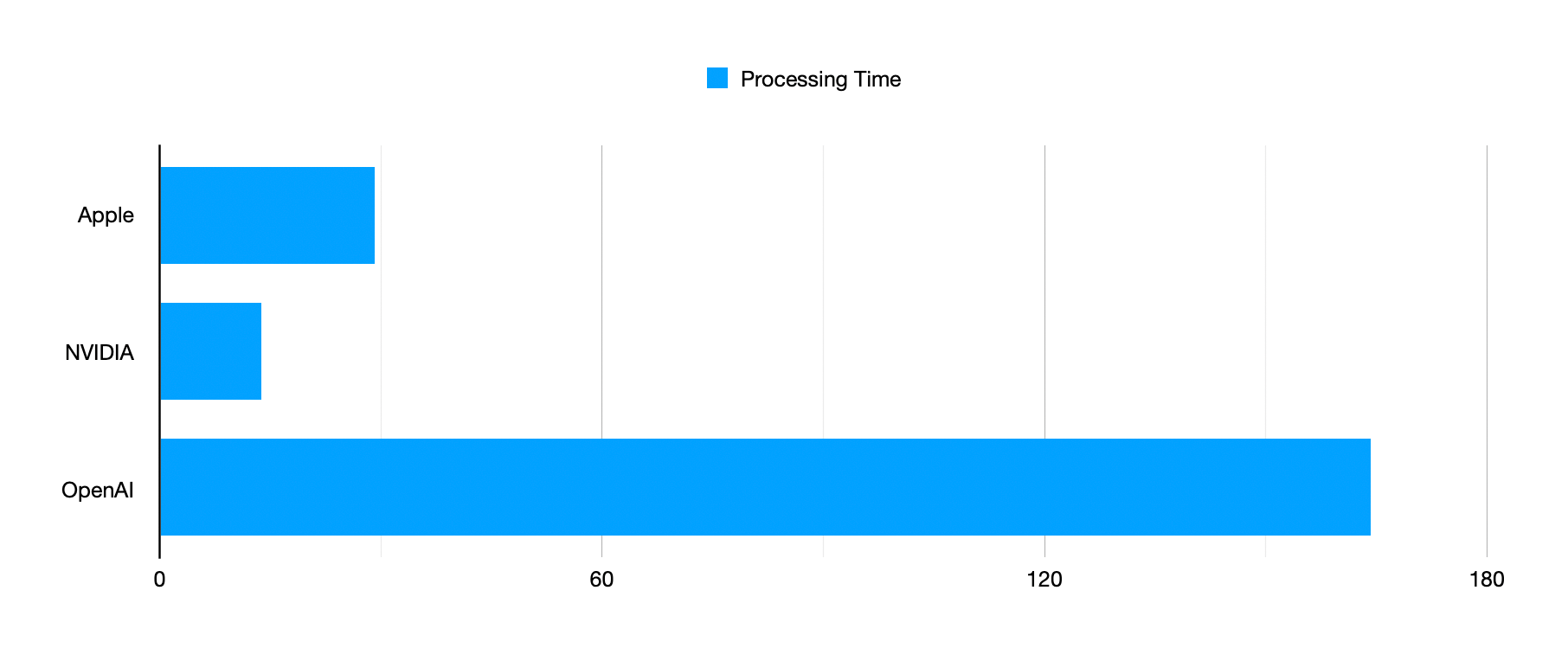
In terms of performance, honestly, all three of these are remarkable compared to what was available to folks five years ago, but obviously the Apple and NVIDIA models are in a whole other class than OpenAI's Whisper when it comes to speed. So why the hell would I add a model that takes 12x more time to process the same file? In a word: accuracy.
Accuracy
Here's what each model delivered for the intro in the most recent episode of Comfort Zone:
Apple Speech Analyzer
Welcome to Comfort Zone, a podcast all about pushing your hosts. Well, outside of their comfort zone. I'm Christopher Lolly, and as always, I am joined by Matt Barcheler. Matt, how are you doing? I'm doing good. I have a little coffee with me today and I am exhausted because I used a manual grinder for the 1st time ever on this, would not advise. It takes forever. That doesn't sound like fun. But we are also joined by the triumphant return of Neelion. Leon, how are you? Hello. I've done better.
NVIDIA Parakeet TDT V3
Welcome to Comfort Zone, a podcast all about pushing your hosts, well, outside of their comfort zone. I'm Christopher Lawley and as always I am joined by Matt Barchler. Matt, how are you doing? I'm doing good. I have a uh a little coffee with me today and I am exhausted because I used a manual grinder for the first time ever on this. Would not advise. It takes forever. That doesn't sound like fun. But we are also joined by the triumphant return of Neilion. Neilion, how are you? Hello, I've done better.
OpenAI Whisper Large V3
Welcome to Comfort Zone, a podcast all about pushing your hosts, well, outside of their comfort zone. I'm Christopher Lawley, and as always, I am joined by Matt Birchler. Matt, how are you doing? I'm doing good. I have a little coffee with me today, and I am exhausted because I used a manual grinder for the first time ever on this. Would not advise. It takes forever. That doesn't sound like fun. But we are also joined by the triumphant return of Nileon. Nileon, how are you? Hello. I've done better.
One of the big features I added in Quick Subtitles 2.0 was a Gemini feature to clean up the transcript to try to account for the issues that Apple's model had. I actually really love that feature myself, and even if no one else ever uses it, I'll still really value it. But the ideal state, of course, is that you never have to make any corrections at all because it just gets it right out of the box. The Whisper model gets us closer than the other two in my testing at being right from the start.
I will say that after nearly a year of using these incredibly fast on-device models, it's a little tough to go back to something this slow, but I am really encouraged by the improved accuracy.
My new default?
Going forward, I think Whisper is going to be my default model, but I'll use Parakeet when I need to batch converts and "pretty good" is good enough. The good news is that I've got the app in a really good place with good options for folks. The bad news, is that despite coming into existence because of Apple's on-device model, it's actually Apple's model that is neither the fastest nor the most accurate, so it's been wedged out for my use of the app.
I currently have two hopes for WWDC in regards to Apple's speech analyzer. First, I hope that they ship an updated version of the model that is improved over what we have now. That's a pretty basic request, so that feels like the baseline. I would also like it if Apple had a more advanced option that developers could use, even if it meant we had to prompt the user to download something extra like we have to do with these other models. Think of it like how they have the enhanced voices that you have to download if you want to use for Siri.
This is fully implemented in my personal dev branch, and I have it working great on iPhone, iPad, and Mac. It's just a matter of doing some more testing, but if all goes well, I would expect this available next week!
Not to make this a pitch for the More Birchtree sub, but they do get TestFlight access to this app and the beta should be out in the next day or two.