Micro app 14: Podcast Transcript Fixer
Today I'm sharing a pretty simple micro-app: a Claude skill that you can use in the desktop app or in Claude Code. It lets you pass in a podcast transcript and helps clean it up for you.
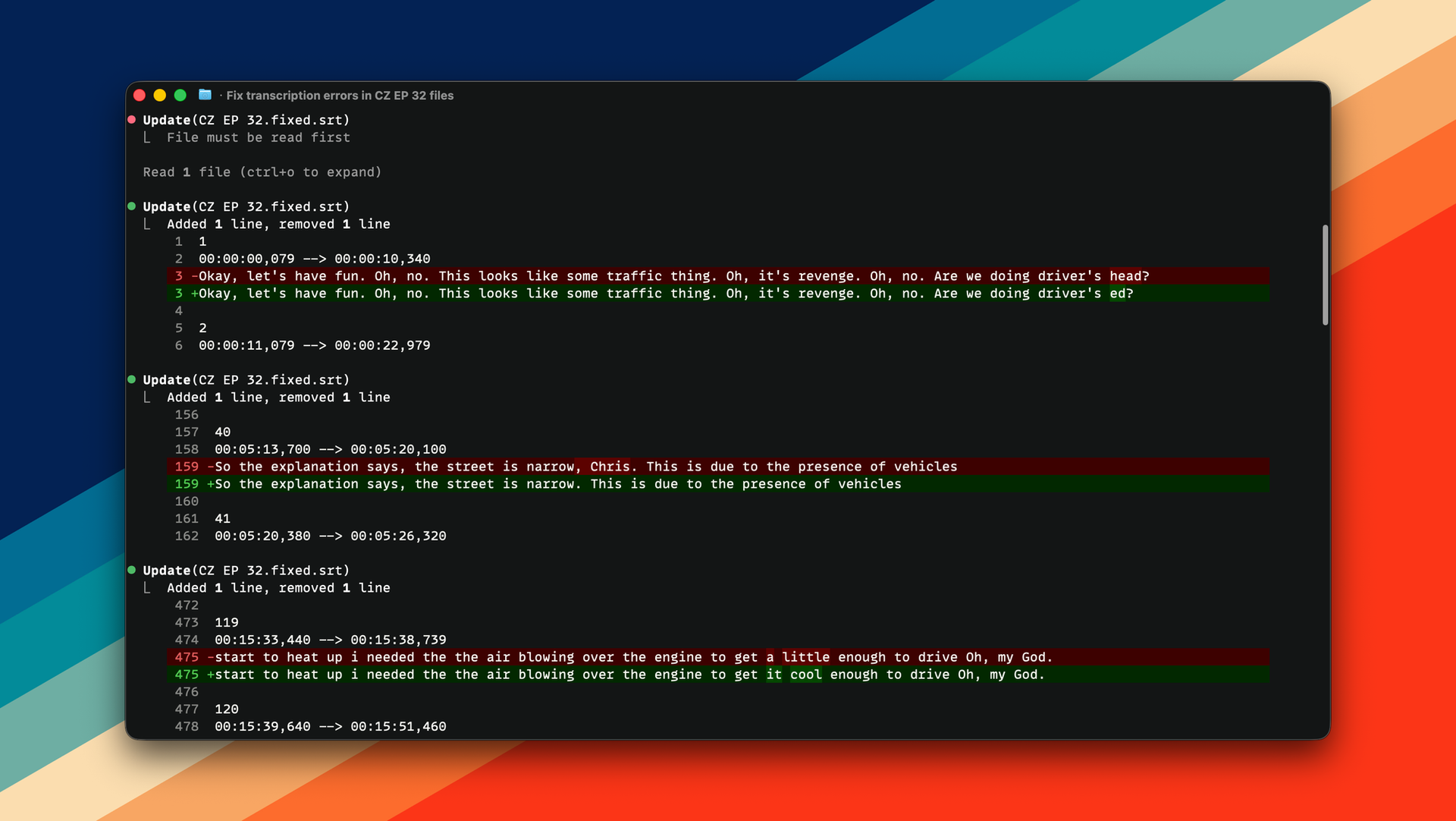
The local models we have today for creating transcriptions are really great, but they aren't perfect, and they do get some things wrong, so it's helpful to clean them up. I've tried to help with this issue before. I implemented a Gemini-powered feature in Quick Subtitles that does this, and it works pretty well, but there are some things I want to improve about that feature, and it's limited to transcripts created in that app. Sometimes I have transcript files that were generated elsewhere, so I needed a more universal way to clean them up. That's where this skill comes in.
Now, I know a good percentage of my readers don't like LLMs and scoff at them as simply being fancy autocorrect, but hey, that's literally what this skill does! It's a fancy autocorrect! Obviously, you can do this without a skill, but skills are effectively shorthand to add to your prompt and to add other considerations that the skill creator may have implemented.
For example, when you use this skill, instead of having a long prompt that explains that this is a podcast transcript and lists the names of the hosts and the sorts of things that it could get wrong, you can just say "clean up this transcript," and it'll go ahead and do it. You can either directly tag the skill, or in most cases, Claude will just understand that you probably want to use the skill and will load it for you.
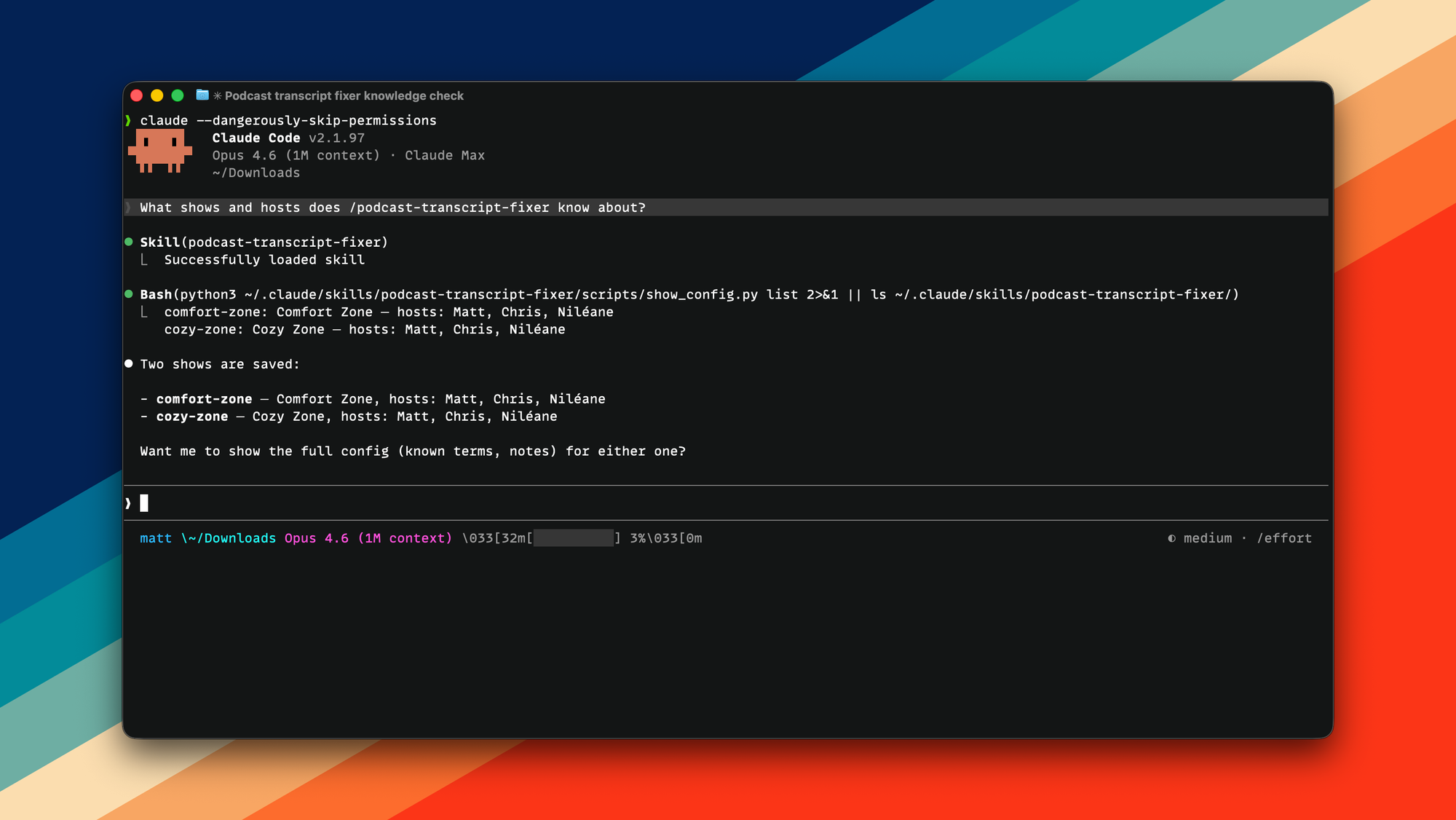
Proper nouns are something that LLMs can often get wrong, especially if they're not typical titles or names. I wanted the skill to be generic, so I didn't hard code anything into it. Instead, I added a memory feature that should make it so that when you first run the skill, it asks you for things like the name of your podcast and the names of the hosts, so it can look up those transcriptions and make sure those are correct. It stores that in Claude's memory, so you don't have to do it every time, although, of course, because Claude is an LLM, you can add these later at any point if you want.
As a quick aside, one of the things that critics of language models often critique is that the output can be a bit fuzzy. Yes, we want the output to be as accurate as possible, but what isn't always appreciated is the fuzzy input, which LLMs excel with. My co-host Nealeon's name is mistranscribed basically every single time by every model, and it's done in different ways. So it's really hard to know exactly what to look for to know what needs to be fixed. A simple find and replace doesn't work super well for this use case, but LLMs can understand that there's a person named Nealeon, and the transcript likely got it wrong, so it will look up possible misspellings and correct multiple of them easily. It's very effective at this, and I really appreciate that about LLMs. When you don't exactly know what you're looking for, but you know what the results should be, it does a really good job at getting you there.
This skill is available for free on GitHub if you'd like to download it, and there are instructions to install it in Claude if you're not familiar with installing skills.