Claude finally gets its “thinking” update
Anthropic released Claude 3.7 yesterday, and as a bit of a Claude stan myself, it’s fair to say I was excited to see it. The last few months have seen meaningful updates to GPT and Gemini, and in an industry moving at this rate, Anthropic felt like they were falling a bit behind.
Today, we’re announcing Claude 3.7 Sonnet, our most intelligent model to date and the first hybrid reasoning model on the market. Claude 3.7 Sonnet can produce near-instant responses or extended, step-by-step thinking that is made visible to the user.
This is very cool, and it largely addresses my complaint from a week ago where I railed against the multitude of model options users have to choose from when using AI models today. Claude’s UI still has a model picker dropdown, and it’s actually got more options than before, but this hybrid model is really good at figuring out how much it needs to “think” about your prompt and dynamically adjusts how it works to do the right thing for you.
We’ve developed Claude 3.7 Sonnet with a different philosophy from other reasoning models on the market. Just as humans use a single brain for both quick responses and deep reflection, we believe reasoning should be an integrated capability of frontier models rather than a separate model entirely. This unified approach also creates a more seamless experience for users.
And:
[I]n developing our reasoning models, we’ve optimized somewhat less for math and computer science competition problems, and instead shifted focus towards real-world tasks that better reflect how businesses actually use LLMs.
These get to the bottom of why I think I personally click with Claude more than the GPT and Gemini models it’s competing with. In some tests, GPT and Gemini score better than Claude, but in my experience using them for all sorts of tasks, Claude is just more reliable at basically everything I use an LLM for day to day. I found this to be remarkably the case when coding my Quick Reviews app in Cursor, where Claude 3.5 simply wiped the floor with GPT o3-mini and Gemini 2 Flash in helping me get usable code into my app. So yeah, these benchmark tests people love to point to are interesting, but my experiences for the things I actually need these models to help me with are always more compelling for me personally.
Claude 3.7 Sonnet is now available on all Claude plans—including Free, Pro, Team, and Enterprise—as well as the Anthropic API, Amazon Bedrock, and Google Cloud’s Vertex AI. Extended thinking mode is available on all surfaces except the free Claude tier.
The cool thing about Claude is that they continue to make their most up to date model available to free users. You don’t get the “extended thinking mode” on the free tier, but even without that you’re still getting the best model they’ve got, and in my book, still the best model out there.
One last thing on pricing:
In both standard and extended thinking modes, Claude 3.7 Sonnet has the same price as its predecessors: $3 per million input tokens and $15 per million output tokens—which includes thinking tokens.
This is more relevant to API integrators, but the cost of using Claud continues to be very high compared to models from other providers. Here’s a comparison of the current models from Anthropic, OpenAI, Google, and Deepseek:
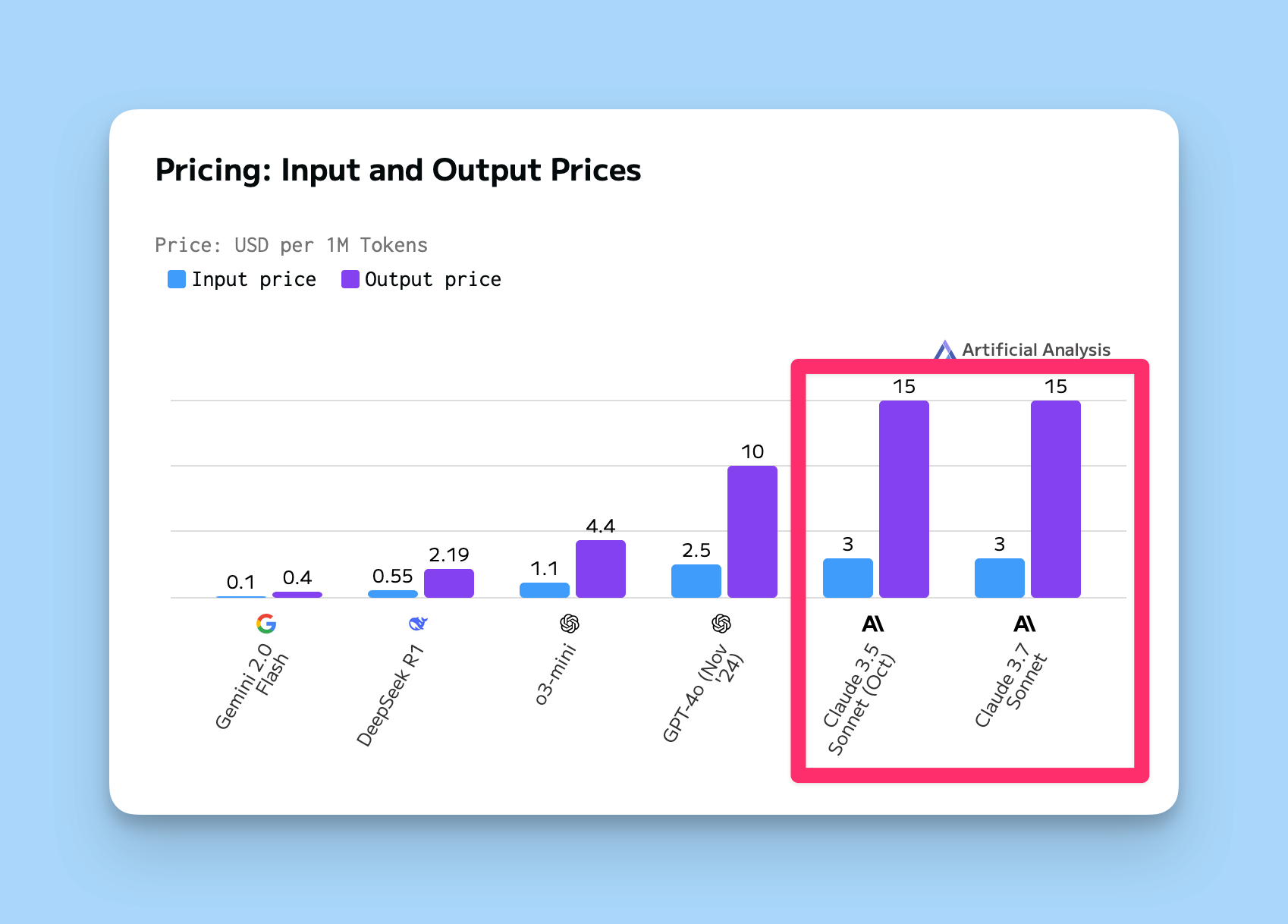
Claude does perform the best for me, so a case can be made that they warrant the increased cost, but as all other models have gotten better and cheaper, it’s notable that Claude has gotten better, but remained very expensive.