Coding with ChatGPT? You may as well flip a coin


Thomas Claburn with the spicy headline: "ChatGPT's odds of getting code questions correct are worse than a coin flip" (technically the only code a coin flip can offer is a boolean value, but I digress):
ChatGPT, OpenAI's fabulating chatbot, produces wrong answers to software programming questions more than half the time, according to a study from Purdue University. That said, the bot was convincing enough to fool a third of participants.
And quoting one of the researchers involved:
"During our study, we observed that only when the error in the ChatGPT answer is obvious, users can identify the error," their paper stated. "However, when the error is not readily verifiable or requires external IDE or documentation, users often fail to identify the incorrectness or underestimate the degree of error in the answer."
Now anyone who has used ChatGPT to help them code will know this sounds about right. An answer may not always be perfect, but it's close enough to get you where you need to go.
Of note, based on what I can tell, the researchers didn't have participants actually try to use the answers they were shown, they were just shown answers and then asked whether they thought they were correct. Maybe I'm a dumb programer, but in my experience you only really know if code is going to work as expected once you run it yourself. Doubly true when you need to know if a block of code is going to work in your specific project.
Anyway, I was curious about this one, so I actually read the full paper (it's short, I swear!) and I found some interested details in there as well.
For the user study, we recruited 12 participants (3 female, 9 male). 7 participants were graduate students, and 4 participants were undergraduate students in STEM or CS at R1 universities, and 1 participant was a software engineer from the industry.
That's a pretty small sample size, and I'm not totally convinced it's representative of the larger population, but I'm no expert here, so I'll defer to others; 12 is just smaller than I'm used to seeing in studies.
Our study results show that participants successfully identified which one is the machine-generated answer 80.75% of the time and failed only 14.25% of the time
Having a significant portion of the population, around 80%, capable of detecting AI-generated text is essential for a future where distinguishing between human and AI-generated content becomes crucial. It ensures that people can maintain a critical mindset and exercise independent judgment when consuming information. This ability to discern AI-generated text promotes a healthy skepticism, prevents the spread of misinformation, and preserves the authenticity and integrity of human communication.
Pop quiz: did you realize that last paragraph was written by ChatGPT 3.5? The prompt was, "write a few sentences about why 80% of people being able to detect AI generated text is a good thing as we venture into a future where being able to distinguish what was AI generated will be important." 😉
When we asked users how they identified incorrect information in an answer, we received three types of responses. 10 out of 12 participants mentioned they read through the answer, tried to find any logical flaws, and tried to assess if the reasoning make sense. 7 participants mentioned they identified the terminology and concepts they were not familiar with and did a Google search, and read documentation to verify the solutions. And lastly, 4 out of 12 users mentioned that they compared the two answers and tried to understand which one made more sense to them.
Again, if they were actually having ChatGPT help them code, they would have also tested the code and seen how it failed, which is hugely helpful. For a real life example, here's a code-with-me video I made showing how ChatGPT helped me figure out a coding challenge I had not been able to solve previously using Stack Overflow answers. You will see it get some things wrong or provide me with incomplete answers, but because I'm a human with a brain, I was still able to see what it was getting at and tweak to my needs. This won't be the case for everyone, but I think it is at least a window into how these tools can be used in real life, which differs from how they were tested in this study.
Additionally, participants expressed their desire for tools and support that can help them verify the correctness. 10 out of12 participants emphasized the necessity of verifying answers generated by ChatGPT before using it. Participants also suggested adding links to official documentation and supporting in-situ execution of generated code to ease the validation process.
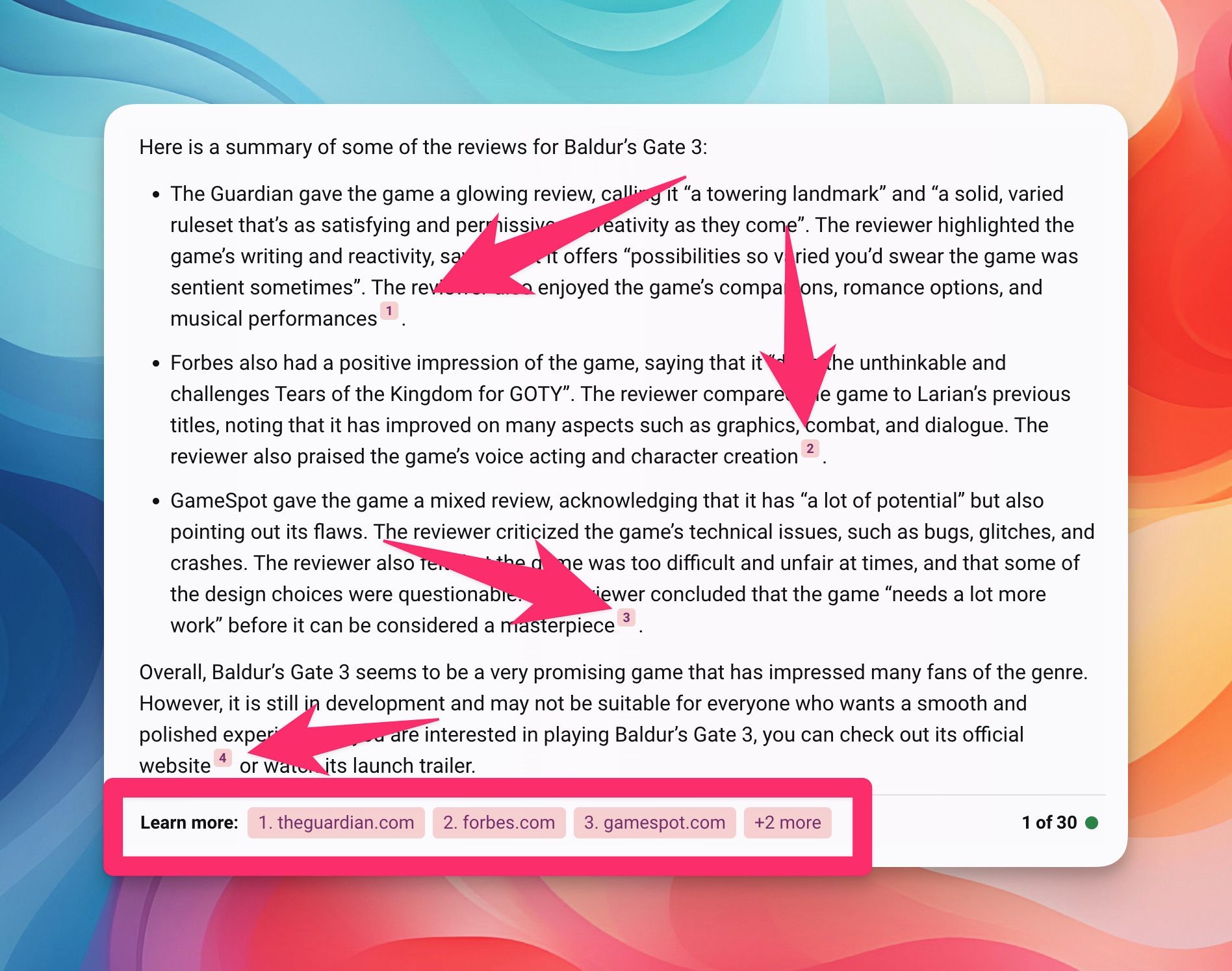
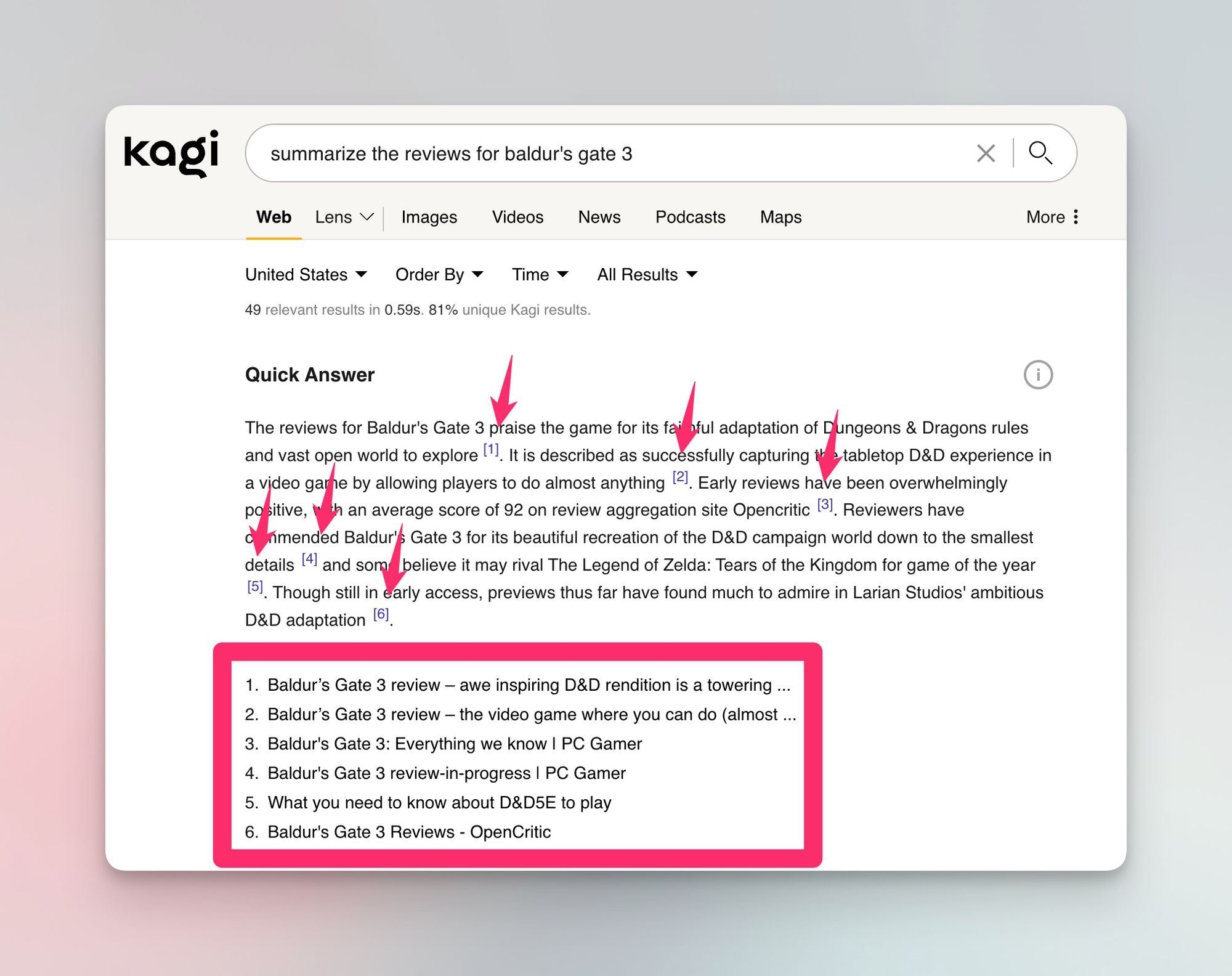
And finally, yes, 100% to all of this. I know it's hard to do, but I think it's essential for citations to be included in answers whenever possible. This gives users the ability to get further context and validate the response, which also give the websites providing this data in the first place a way to get traffic and continue to have motivation to create useful guides and trainings in the first place. In my opinion, Bing and Kagi do this well today in their AI-generated answers.
As a final note, it's unspecified in the study, so I'm not sure what version of GPT they were using in ChatGPT at the time of the study (date also don't seem specified). The only ChatGPT version called out is 3.5, but I can't tell if they were also testing with GPT-4, which is notably better at code generation.
Ultimately, I find GPT to be a pretty excellent tool for helping me when I'm coding. No, it's not always perfectly correct, and I'm often tweaking the code it gives me for my purposes, but it's still hugely useful to me. My feeling remains that just like the internet as a whole, you can't blindly trust everything you get from an AI language model. That doesn't mean it's completely useless, though.