Terrible Benchmarks and AI Text Generators
I keep seeing people trying to show how stupid these AI text generators are by giving them inane tasks that someone would only do to…um…test AI text generators. Here’s an example I saw today (nothing but love to Daniel Jalkut, btw):
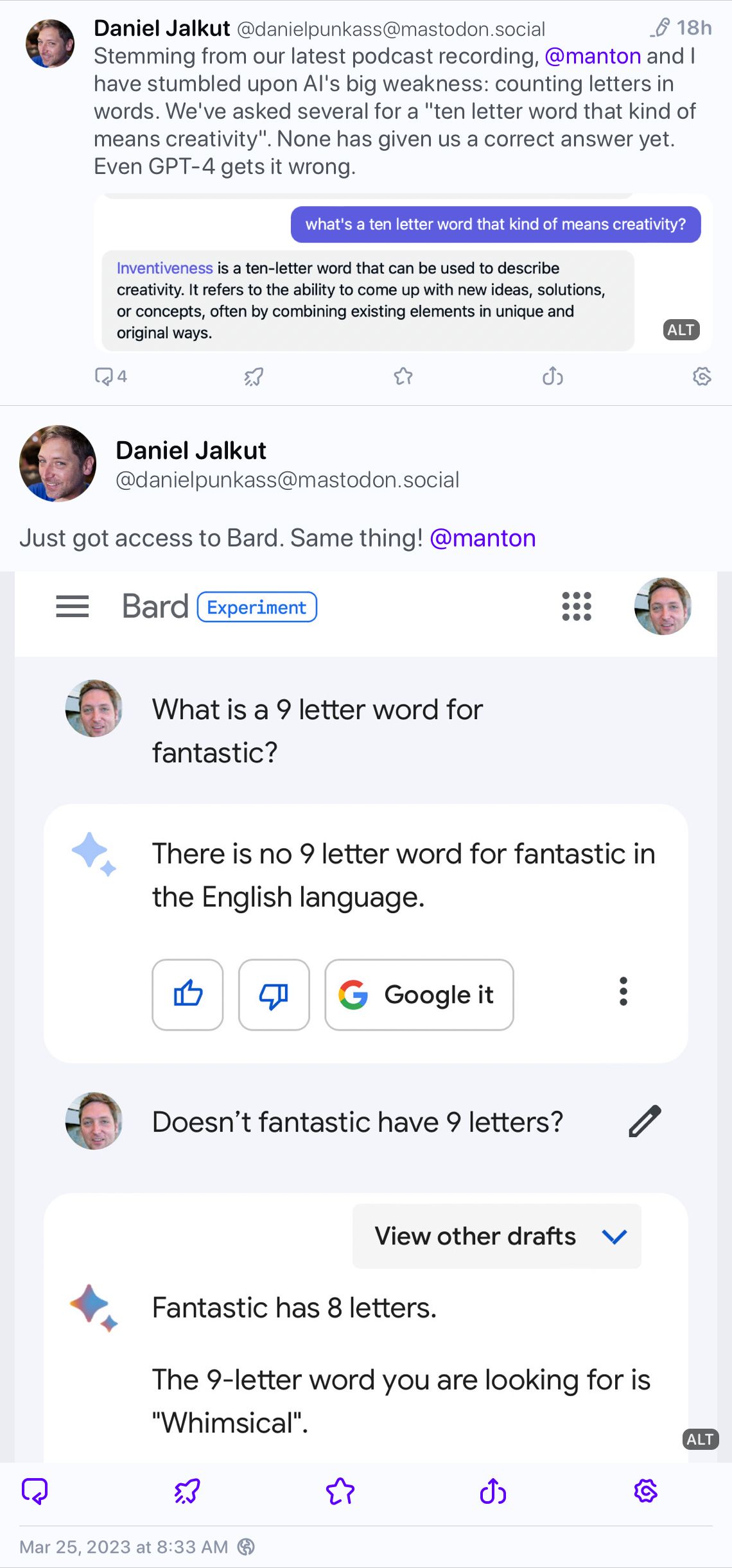
On the one hard, yes, this lets you go “haha, this is so stupid,” but on the other hard, who cares? Unless you’re going to use these tools to help you finish a crossword puzzle, is this the sort of thing you’d ever want to do outside of proving how braindead these things are?
Here’s an example search I did yesterday for a question I had about the brand new Resident Evil 4 game that just came out.
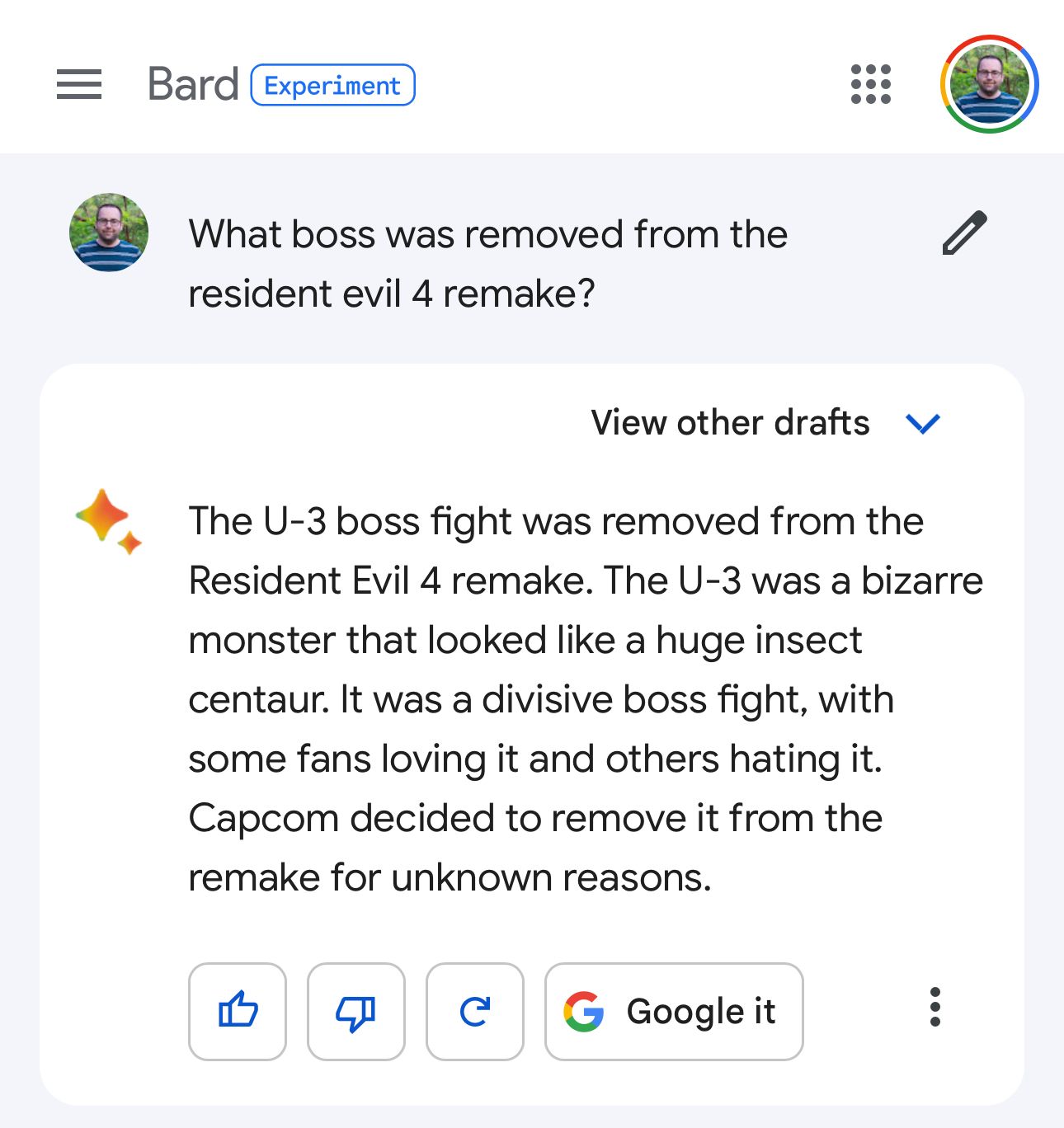
This is great! It’s a timely question and it gives me the answer perfectly.
Incidentally, I will also bring up that Google needs to get citations into their Bard answer ASAP. It does return them sometimes, but it’s vey rare. Meanwhile, Bing reliably links to every source it’s using to get each piece of information in its answers. This is better for users and for publishers, and Google needs to get on Bing’s level before this goes wide.
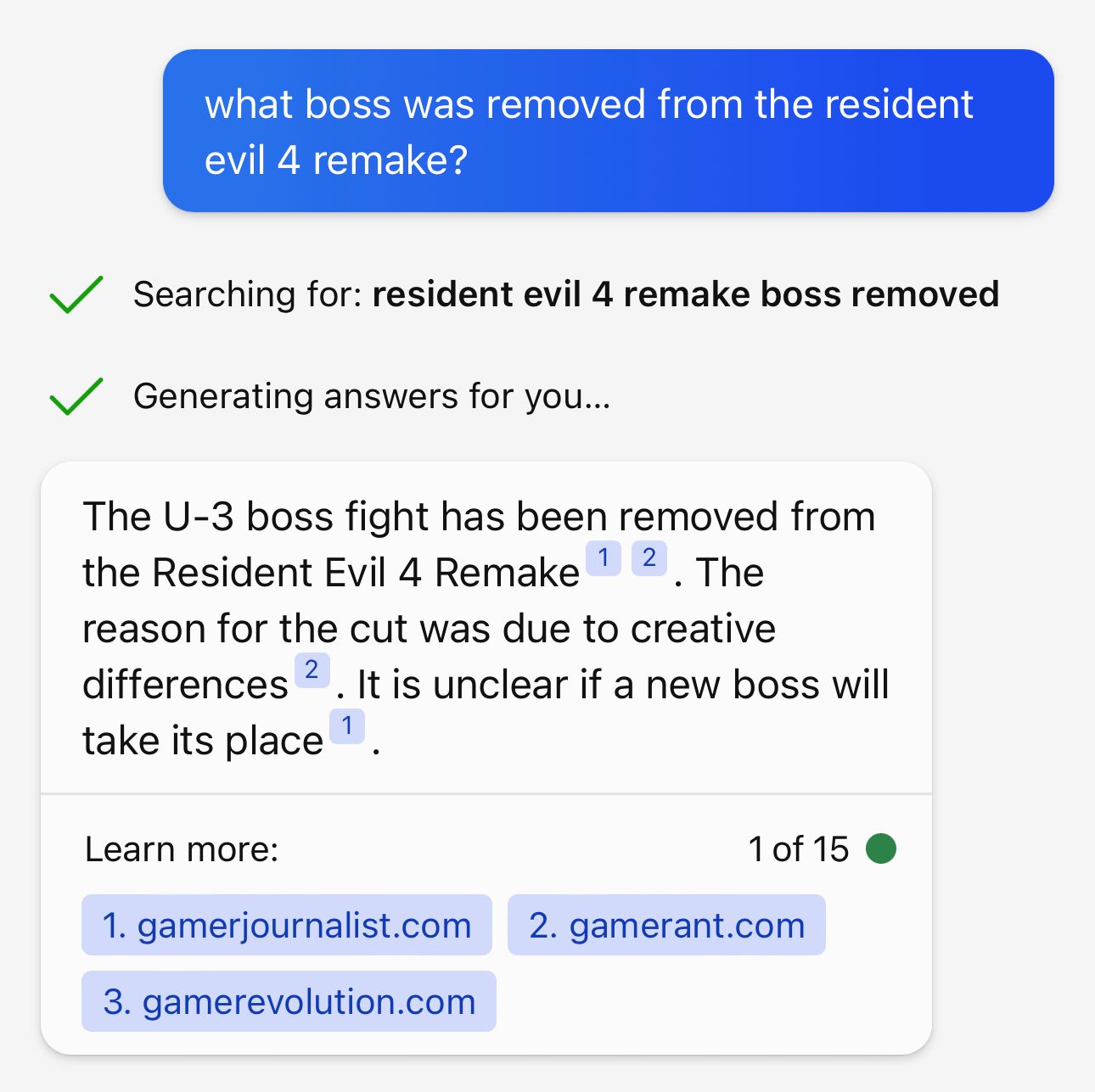
If you instinctually dislike these LLMs, then I understand the cathartic joy of “tricking” them with silly questions, but many of the “look how stupid these things are” gotchas I’m seeing are at best academically interesting, but not actually useful for much more than that.





